Deployment architecture
Our recommended approach to deployment is to setup a containerised environment that allows for replication of services. This allows the infrastructure to be scaled horizontally as load increases as well as enabled fail safe behaviour if you loose some services. In addition the use of containerisation allows for deployment in a range of hosting environments keeping project flexible. If your project calls for particular hosting platforms, then not all of these pattern may apply.
We also encourage the use of clustered database configuration which will depend on the database software that you are using in your project. Sometimes this is easier handled outside of the replicated container environment, but that depends on the project and the software at play. Also note: when considering replicated database setups it's often useful to consider having replicas in geographically distinct regions.
Note: This complexity is the general pattern, however if the problem you are solving is simple, doesn't anticipate much load and some down time is acceptable (e.g. pilots or proof of concepts) then this setup may not be necessary but we usually find at least containerisation useful.
A generalised deployment architecture diagram describing the approach is show below:
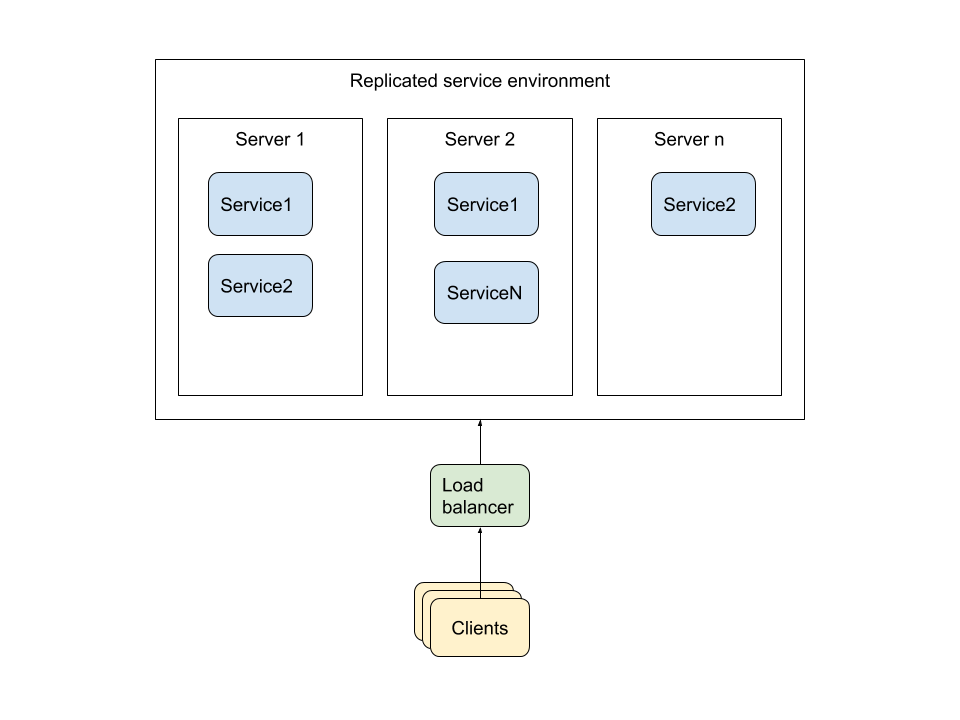
Deployment Technologies
The technologies that Jembi recommends to achieve this style of deployment architecture are as follows:
- Ansible - to configure fresh servers with a baseline config e.g. installing docker, instantiating a cluster, giving users access to server and configuring firewall rules.
- Docker - to build our applications and services into docker images which allows us to easily deploy them in a multitude of environments and configurations. We recommend enabling the use of environment variables to configure docker images so the same image may be used within different environments.
- Docker Compose - to stand up a set of services and/or apps that work together as a software stack e.g. databases, services and webapps
- Docker Swarm/Kubernetes - to orchestrate the deployment of the stack. This includes spreading the stack over multiple servers and replicating services within the stack. This is what gives us high-availability and enables scalability. Here is some guidance in choosing between the two:
- Kubernetes has been tried and tested and has a lot of support in the development community, however, it can be very difficult to install and manage on bare metal or on any custom platform. Many major hosting provides provide Kubernetes support as standard so this may not be an issue if you are using hosting provider such as AWS, Digital Ocean or Azure.
- Docker swarm is a newer technology and while very stable doesn't have the support and feature set of Kubernetes, however it is very easy to get up and running by yourself on bare metal or locally and it fits in very well with the existing Docker suite of tooling. It is much easier to install and manage if you need to run on multiple platforms or on bare metal servers.
- Traefik/Nginx - to load balance between services. Traefik has the additional benefit of integrating with docker and automatically setting up routing based on docker labels as well as automatically generating let's encrypt certificates for you.
A number of projects maintain infrastructure scripts in this internal repo and some host their own infrastructure scripts either alongside of the source code or is a separate repository.
We recommend running infrastructure scripts often, preferably during CI tasks to deploy to a staging environment. This ensures that the scripts are kept updated and it is much less painful to do real production or QA deployments.
Managing docker compose files for multiple environments
Writing multiple separate docker-compose files for different environments such as dev, QA and production is a pain if you have to try keep them all in sync. The recommended strategy to do this is to use docker compose's override files feature. This enabled you to override a docker-compose files with one or more other docker-compose files which change the configuration of particular services or add additional services.
For example, a useful structure for compose files is as follows:
docker-compose.yml- contains all the services you are coding with default configurationdocker-compose.deps.yml- contains all the service for the project's dependencies with default configuration e.g. databasesdocker-compose.dev.yml- contains development overrides e.g. perhaps you can expose all the services ports to your local machine so that debugging is easier and you could enable development logging configurationdocker-compose.dev-deps.yml- contains development overrides for your dependenciesdocker-compose.deploy.yml- contains production overrides e.g. to add docker secrets for sensitive info, add a load balancer configuration and set service replication defaults
Then you could use these as follows. The first compose file argument given is used as the base and each following compose file extends the overall configuration:
- To run a development environment:
docker-compose -p <project_name> -f docker-compose.yml -f docker-compose.deps.yml -f docker-compose.dev-deps.yml -f docker-compose.dev.yml up - To run just the project dependencies:
docker-compose -p <project_name> -f docker-compose.deps.yml -f docker-compose.dev-deps.yml up - To deploy to production on docker swarm:
docker stack deploy -c docker-compose.deps.yml -c docker-compose.yml -c docker-compose.deploy.yml <project_name>
This strategy allows maximum reuse in your compose files so that your development environment can be run in almost the exact some environment as production.